RAG介绍
2026/2/17大约 2 分钟
RAG介绍
什么是RAG
RAG就是在向模型提问之前基于已有的知识库或文档内容做检索,确保向模型提问的内容更精准以及包含足够的信息量用以提供给模型。RAG(Retrieval-Augmented Generation)即检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案。可以总结为一个公式:RAG = 检索技术 + LLM 提示。
RAG作用:
- 解决知识实效性问题:大模型的训练数据有截止时间,RAG 可以接入最新文档(如公司财报、政策文件),让模型输出 “与时俱进”。
- 降低模型幻觉:模型的回答基于检索到的事实性资料,而非纯靠自身记忆,大幅减少编造信息的概率。
- 无需重新训练模型:相比微调(Fine-tuning),RAG 只需更新知识库,成本更低、效率更高。
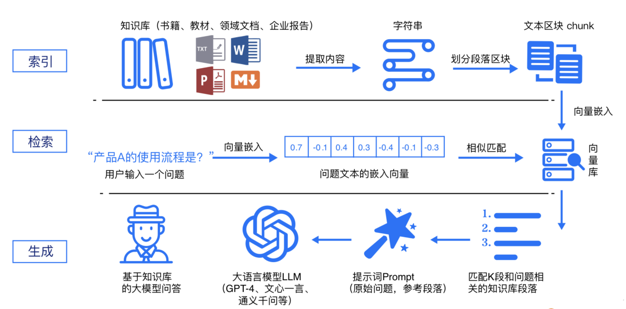
RAG 标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
- 索引阶段
通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。
- 加载文件
- 内容提取
- 文本分割 ,形成chunk
- 文本向量化
- 存向量数据库
- 检索阶段
用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
- query向量化
- 在文本向量中匹配出与问句向量相似的top_k个
- 生成阶段
检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
- 匹配出的文本作为上下文和问题一起添加到prompt中
- 提交给LLM生成答案: